
Annotating Large Datasets with the TensorFlow Object Detection API
 Detections of race cars, after training on a small dataset containing only 60 images
Detections of race cars, after training on a small dataset containing only 60 images
When building datasets for machine learning object detection and recognition models, generating annotations for all of the images in the dataset can be very time consuming. These annotations are required to train and test a model, and they must be accurate. For this reason, human oversight is required for all of the images in a dataset. However, that does not mean that machine learning models cannot be of assistance.
Checking and correcting a set of mostly correct annotations is generally a less time consuming task than creating a complete set of new annotations. When working on a dataset containing thousands of images, saving a few seconds per image could save several hours of work.
The purpose of this article is to prove that for object recognition and detection tasks where high accuracy is not a necessity, small datasets and “out of the box” models can provide useful results.
Using the example of detecting race cars in an image, this article will guide through the following steps.
- Annotating images in a small dataset.
- Training a primitive model from this dataset.
- Use this primitive model to predict the annotations on images from a new dataset.
This article has a repository on GitHub that contains some example code and data. It will be assumed that the TensorFlow Object Detection API has been installed.
Annotating Images
An easy format to use for image annotations is the PASCAL VOC file format. This is an XML file format used by Image Net. The LabelImg program is an excellent tool that can be used to generate and modify annotations of this format.
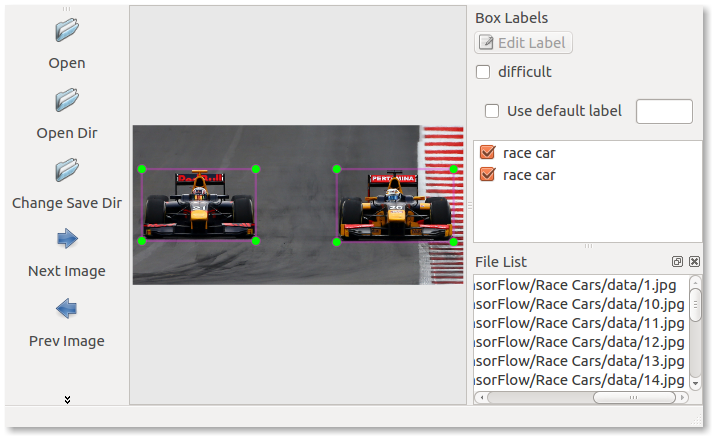
The data directory in the example repository shows annotations generated using this method. The label map file will need to be created manually, as this is not produced by LabelImg.
Training the Primitive Model
The TensorFlow Object Detection API provides detailed documentation on adapting and using existing models with custom datasets.
The basic process for training a model is:
- Convert the PASCAL VOC primitive dataset to a TFRecord file. The example repository provides a python script that can be used to do this.
- Create an object detection pipeline. The project hosts official documentation on how to do this and there is an example in the repository. The example in the repository is based upon the
ssd_mobilenet_v1_cococheckpoint, there are a number of provided checkpoints that can be downloaded from the official documentation. - Train the primitive model. This can be done locally or on the Google Cloud Platform. The results obtained in this article were from around 10,000 steps.
- Export the last checkpoint to an inference graph.
The end result of this process will be a file named frozen_inference_graph.pb. This is the model that can be used to predict annotations.
Predicting Annotations
The pascal-voc-writer library can be used to generate annotations in the PASCAL VOC file format. It has a simple to use API, and the code below shows an example of adding a ‘cat’ annotation to an image.
from pascal_voc_writer import Writer
writer = Writer('path/to/img.jpg', 800, 400)
writer.addObject('cat', 100, 100, 200, 200)
writer.save('path/to/img.xml')
The annotate.py file in the example repository uses this library to adapt the inference example from the official documentation to create PASCAL VOC annotation files rather than image visualisations.
The threshold score for an annotation to be produced can be optimised to suit the dataset and the needs of the operator. The threshold score should balance the frequency of unhelpful annotations against the miss rate. If removing unhelpful annotations is easier for the operator than generating missed ones, a lower threshold score should be used to reflect this.
Below are three more predictions from the primitive model. Despite having a very small dataset and only a few training steps, the model has made useful predictions that would save time annotating these images.
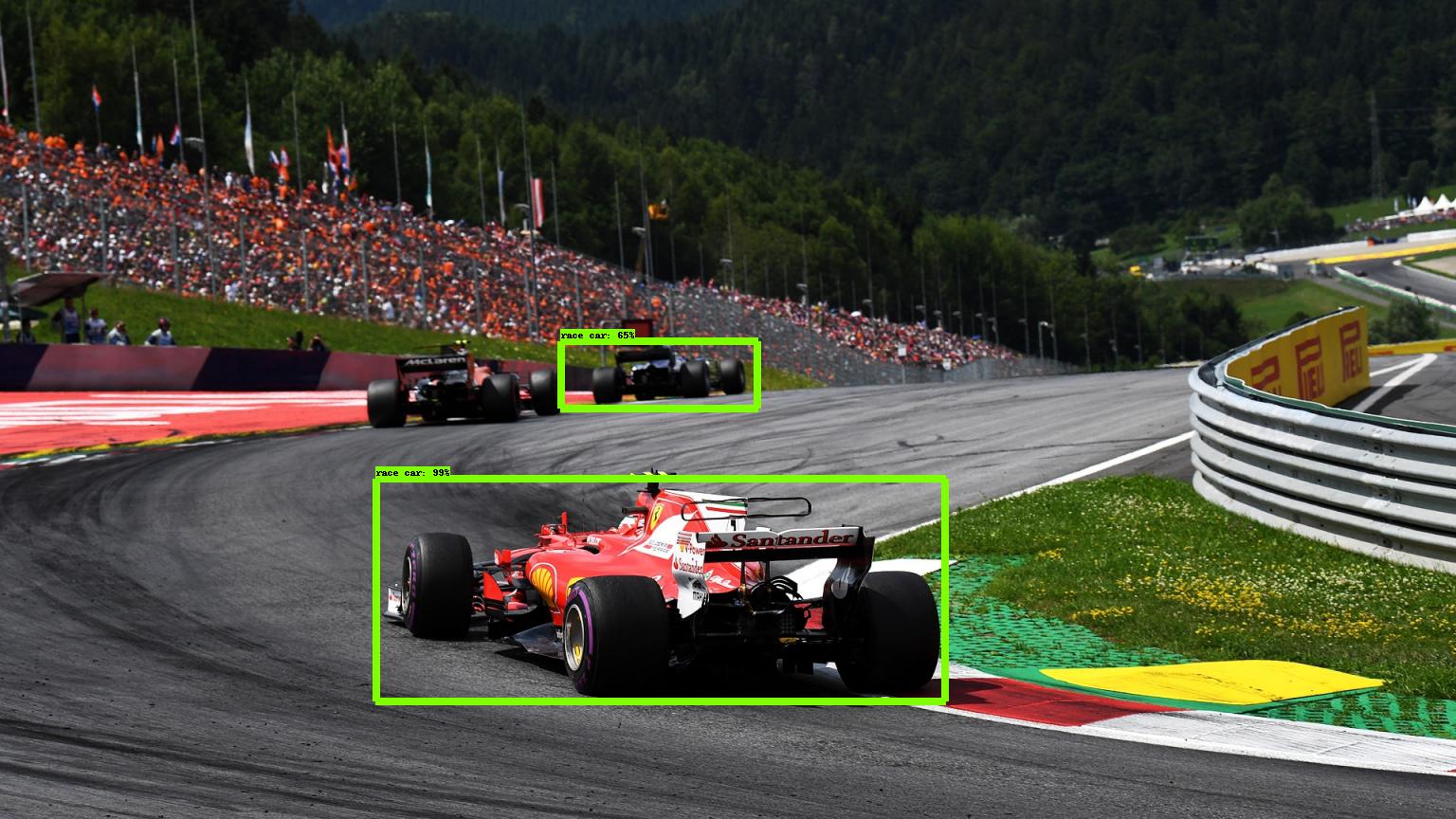 In this example two annotations are correctly suggested and one is missed. The suggested annotations on the furthest car could be shrunk slightly.
In this example two annotations are correctly suggested and one is missed. The suggested annotations on the furthest car could be shrunk slightly.
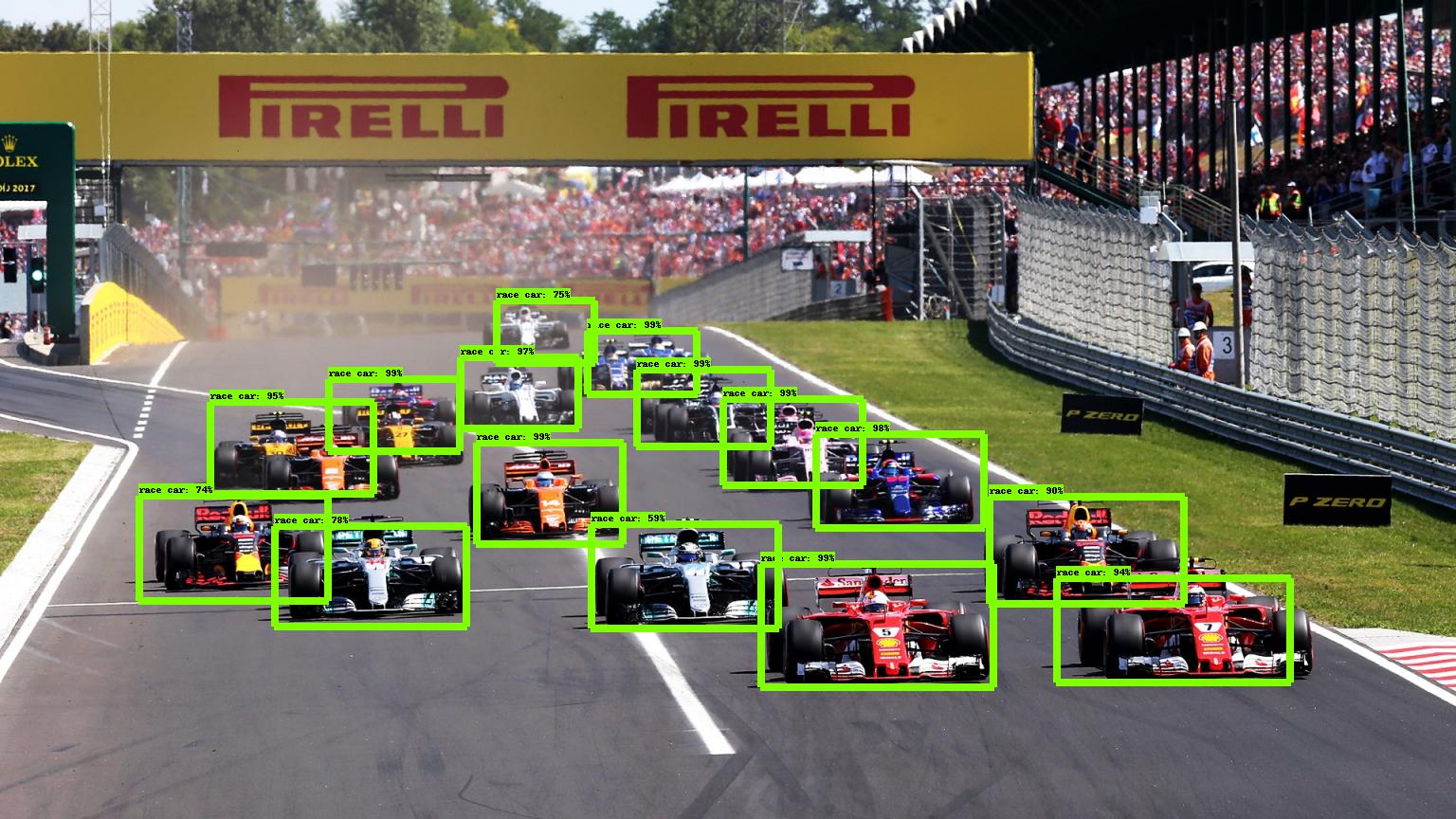 These images take a long time to annotate manually. The primitive model has done a reasonable job at cutting out the bulk of the workload. It has struggled in the case of some of the obscured cars, but some of the obscured cars would be difficult for humans to spot.
These images take a long time to annotate manually. The primitive model has done a reasonable job at cutting out the bulk of the workload. It has struggled in the case of some of the obscured cars, but some of the obscured cars would be difficult for humans to spot.
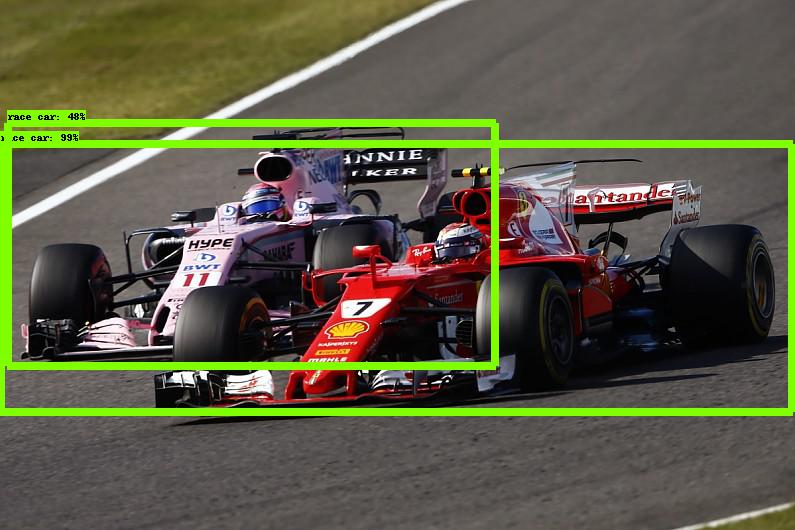 Both cars are identified, however the bounding box is far too wide for the closest car.
Both cars are identified, however the bounding box is far too wide for the closest car.